Substra overview¶
Contents
Assets¶
Assets are a set of files which are required to run a compute plan. In order to enable privacy-preserving machine learning, different types of assets live within the platform: datasets, functions, models, tasks and compute plans.
Dataset¶
A dataset represents the data in Substra. It is made up of:
An opener, which is a script used to load data from files into memory.
At least one data sample - a data sample being a folder containing the data files.
Compute plan and tasks¶
Compute plan¶
A set of tasks. Gathering tasks into a single compute plan will lead to a more optimized compute.
Note that you can register a task alone, i.e. not put the task in a compute plan, but Substra will still create a compute plan for you for this specific task.
Task¶
A task correspond to a computation task. The task can use any inputs (data, functions or output from other tasks). The function is expected to write the outputs in files, on paths given as outputs dictionary.
Rank¶
A task’s rank is the mathematical order (or graph depth) of this task within a compute plan. A task of rank n will depend on the output of tasks of rank n-1.
Note that a task of rank n will not necessarily depend on all the tasks with rank n-1. This means that tasks of rank n can start before tasks of rank n-1 if they have no direct link with each other.
Transient task outputs¶
Task outputs flagged as transient are deleted from the storage when all the tasks depending on this output are complete.
This prevents filling up your server with outputs that you will not use in the future.
Permissions¶
All assets metadata are visible by all the users of a channel. So if a user registers a new function or a new dataset, every user of this channel will be able to see the asset medatata (name, creation date, etc). However processing the asset will need specific permissions.
In particular for datasets:
Data can not be seen once it’s registered on a Substra platform.
Like other assets, all dataset metadata are visible by all the users of a channel.
Having process permissions for a dataset means having permissions to execute a function on this dataset.
Permissions for an organization to process an asset¶
An organization can execute a task if it has the permission to process all the inputs of the task. The permission on an asset is defined when creating the asset or when creating the task that will create the asset. Permissions can be defined individually for every organization. Permissions cannot be modified once the asset (or the task producing the asset) is created.
Permissions for a user to download an asset¶
Users of a organization can export (aka download) the following elements from Substra to their local environment:
The opener of a dataset if the organization has process permissions on the dataset.
The archive of a function if the organization has process permissions on the function.
The model outputted by a task if the organization has process permissions on the model AND if this type of export has been enabled at deployment for the organization. This means the value
model_export_enabledshould be set toTruein the organization’s backend.
Permissions summary table¶
In the following tables, the asset is registered by orgA with the permissions:
{public: False, authorized_ids: [orgA, orgB]}
Organization |
What can the organization do? |
Can the user of the organization export the asset? |
|---|---|---|
orgA |
orgA can run tasks on this dataset on orgA |
Yes - opener only |
orgB |
orgB can run tasks on this dataset on orgA |
Yes - opener only |
orgC |
Nothing |
No |
Organization |
What can the organization do? |
Can the user of the organization export the asset? |
|---|---|---|
orgA |
orgA can use the function in a task on any organization |
Yes - the function archive |
orgB |
orgB can use the function in a task on any organization |
Yes - the function archive |
orgC |
Nothing |
No |
Parallelization¶
There are two ways to run several tasks in parallel on a same organization with Substra. The first one, named vertical scaling, is when several tasks are run in parallel on the same machine. The second one, horizontal scaling, is when several tasks are run in parallel on several machines belonging to the same organization.
Substra channels¶
A channel is a group of Substra organizations which operates on a common set of assets.
Having multiple channels is needed if you want to have multiple independent projects on the same network.
In the scheme below, we represent a Substra network with two channels:
Channel A with the three organizations
Channel B with only two organizations (A and B)
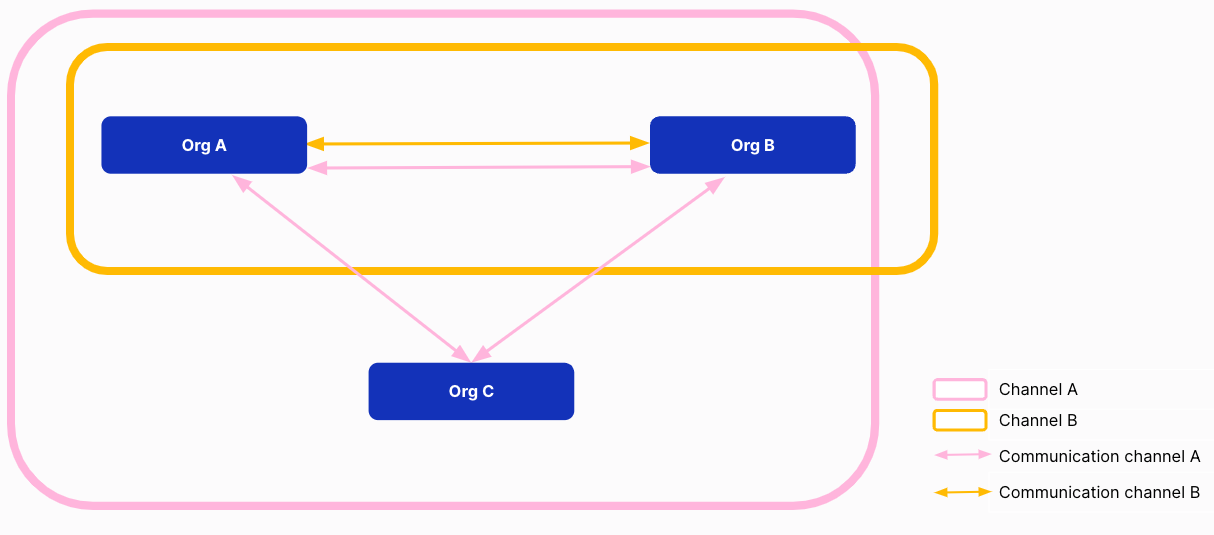
Users only belong to one channel¶
A user can only belong to one channel. A channel has its own users, its own datasets, compute plans, tasks and functions – all invisible to users from other channels. A user from another channel has no visibility on this. A user has no visibility on a channel they are not a part of.
Multiple tasks from different channels¶
Tasks from different channel will be executed in the order of submission to the organization. First in first out (FIFO). If a user from channel A stacked up a lot of tasks before a user from channel B, all tasks from channel B will wait for channel A tasks to finish. This might be confusing for channel B users, as they have no visibility on channel A tasks status.
User management¶
There are two types of users: admin and users. The only difference is that admins can create and delete any Substra users or admins, whereas users can not perform any user management task. Users are managed in the web application.
Compute plan execution - deployed mode¶
This section describes what happens during the compute plan execution in deployed mode and what can be done to improve the execution time. In local mode, these steps are either skipped or simplified.
Once a compute plan is submitted to the platform, its tasks are scheduled to be executed on each organization.
On each organization, Substra fetches the assets needed for the first task, builds the Docker image of the function and creates a container with the relevant assets. The task executes and Substra saves its outputs. Afterwards, every task from the same compute plan that uses the same function is executed in the same container.
Asset preparation¶
The first step of the task execution is to fetch the necessary assets. These include the inputs (e.g. the function or opener files), the output of other tasks (input artifacts of the task) and data samples.
The assets, data samples excluded, come from the file systems of the organizations. If they are stored on other organizations, they are downloaded over HTTPS connections. (for examples, a function submitted on another organization).
All the organization data is stored on the organization storage solution (MiniO). The task data samples are downloaded from the organization storage solution to the organization filesystem which may take a long time if the dataset is large. Note that data samples never leave the organization. Example: depending on the deployment configuration, downloading hundreds of gigabytes may take a few hours.
Since this step can be quite long, there is a cache system: on a given organization, all the downloaded files (assets and data samples) are saved on disk. This means when another task reuses the same assets there is no need to download them again. Once the cache is full, the worker deletes all its content.
Docker image build¶
For the first task of the compute plan that uses a given function, Substra needs to build the image, transfer it to the local image registry, and then use it to spawn the container. This takes a few minutes for a small image and can take longer for larger images.
For the tasks in the same compute plan that use either the same function or a different function with the same Docker image, Substra does not need to rebuild the image, making the task execution much faster.
To check how large the image is and how long it takes to build, you can build it locally with docker build ..
For hints on how to make the Docker image smaller and faster to build, see the Docker documentation.