Release notes¶
Compatibility table¶
These sets of versions have been tested for compatibility:
release |
substrafl |
substra |
substra-tools |
substra-backend |
orchestrator |
substra-frontend |
hlf-k8s |
substra-tests |
|||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
app |
helm | app |
helm | app |
helm | app |
helm | ||||||||||
| 0.26.2 | 22.4.2 | 7.4.12 | 1.0.16 | 10.2.3 | |||||||||||||
| 0.26.1 | 22.4.2 | 7.4.12 | 1.0.16 | 10.2.3 | |||||||||||||
| 0.26.0 | 22.4.2 | 7.4.12 | 1.0.16 | 10.2.3 | |||||||||||||
| 0.25.0 | 22.3.3 | 7.4.10 | 1.0.14 | 10.2.3 | |||||||||||||
| 0.24.0 | 22.2.4 | 7.4.8 | 1.0.11 | 10.2.2 | |||||||||||||
| 0.23.1 | 22.2.2 | 7.4.6 | 1.0.9 | 10.2.2 | |||||||||||||
| 0.22.0 | 22.1.2 | 7.4.4 | 1.0.7 | 10.2.2 | |||||||||||||
| 0.21.0 | 22.0.3 | 7.4.2 | 1.0.6 | 10.2.2 | |||||||||||||
Changelog¶
This is an overview of the main changes, please have a look at the changelog of every repository to have a full grasp on what has changed:
Substra 0.26.2 — 2023-04-19¶
Fix Binder build for documentation examples
Add hardware requirements documentation
Substra 0.26.1 — 2023-04-11¶
Optimising the Dockerfiles generated by SubstraFL for faster image builds
Substra 0.26.0 — 2023-04-03¶
Improve backend performance when handling large amounts of compute plans and tasks. This will result in faster front-end pages.
Rename Algo to Function.
SSO Login
Experimental: Add a task duration breakdown for every task in the front-end. Note that this is an experimental feature and only works on the current backend you are logged into.
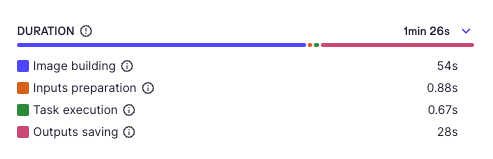
Front-end:
Fix issue where a performance of
0was displayed as-.
SubstraFL:
BREAKING CHANGE:
algoare now passed as a parameter to thestrategyand not toexecute_experiementanymore.BREAKING CHANGE: a
strategyneeds to implement a new methodbuild_graphto build the graph of tasks to be executed inexecute_experiment.BREAKING CHANGE:
predictmethod ofstrategyhas been renamed toperform_predict.BREAKING CHANGE: clarify
EvaluationStrategyarguments: changeroundstoeval_frequencyandeval_rounds.Fix an issue where
aggregation_lrcould not be changed in the Scaffold strategy.Add Initialization task to each strategy in SubstraFL
Substra 0.25.0 — 2023-02-17¶
BREAKING CHANGE:
DataSampleSpecdoes not have atest_onlyfield anymore.SubstraFL: It is now possible to test on an organization where no training have been performed.
New
creatorfield in Compute Plan.Fix an issue where Skaffold spawned too many backends.
Add contributing guide & code of conduct to all repos.
Substra 0.24.0 — 2023-01-13¶
Fix issue where launching a large compute sometimes fails with:
ERROR: could not serialize access due to read/write dependencies among transactions (SQLSTATE 40001)Documentation: add contributing guide and code of conduct
Update Substra Tools base docker image to
substra-tools:0.20.0-nvidiacuda11.6.0-base-ubuntu20.04-python3.*
Substra 0.23.1 — 2022-11-24¶
Main changes
BREAKING CHANGE: replace the tasks
traintuple,aggregatetuple,predicttuple,testtuple,composite_traintuplewith a single task.
task_key = client.add_task(
substra.schemas.TaskSpec(
algo_key=algo_key,
worker=client.organization_info().organization_id, # org on which the task is executed
inputs=[
{
'identifier': 'datasamples',
'asset_key': datasample_key
},
{
'identifier': 'opener',
'asset_key': dataset_key
}
],
outputs= {
'example_output': {
'permissions': {
'public': False,
'authorized_ids': ['org1'],
},
'is_transient': True,
}
}
)
)
task = client.get_task(task_key)
tasks = client.list_task()
# Compute plan changes
compute_plan = client.add_compute_plan(
substra.schemas.ComputePlanSpec(
name = 'my compute plan',
tasks = [
schemas.ComputePlanTaskSpec(
task_id=uuid.uuid4(),
algo_key=algo_key,
worker=client.organization_info().organization_id, # org on which the task is executed
inputs=[
{
'identifier': 'datasamples',
'asset_key': datasample_key
},
{
'identifier': 'opener',
'asset_key': dataset_key
}
],
outputs= {
'example_output': {
'permissions': {
'public': False,
'authorized_ids': ['org1'],
},
'is_transient': True,
}
}
)
]
)
)
SubstraFL
The metric registration is simplified. The user can now directly write a metric function within their script, and directly register it by specifying the right dependencies and permissions. The metric function must have (
datasamples,predictions_path) as signature.
Example of new metric registration:
metric_deps = Dependency(pypi_dependencies=["numpy==1.23.1"])
permissions_metric = Permissions(public=True)
def mse(datasamples, predictions_path):
y_true = datasamples["target"]
y_pred = np.load(predictions_path)
return np.mean((y_true - y_pred)**2)
metric_key = add_metric(
client=substra_client,
permissions=permissions_metric,
dependencies=metric_deps,
metric_function=mse,
)
The round 0 is now exposed. Possibility to evaluate centralized strategies before any training (FedAvg, NR, Scaffold). The round 0 is skipped for single org strategy and cannot be evaluated before training.
Add support for Python 3.10.
Local dependencies are installed in one pip command to optimize the installation and avoid incompatibilities error.
Fix error when installing current package as local dependency.
Substra:
Add Windows compatibility for Docker mode.
BREAKING CHANGE remove category from
substra.schema.AlgoSpecandsubstra.models.Algo
Web application:
Add documentation link in user menu.
Removed task categories from the frontend.
Renamed any tuple thing into a task thing.
Check for last admin when editing a user.
Build error logs are now accessible given the right permissions.
Substra-Tools:
Update Substra Tools base docker image to
substra-tools:0.19.0-nvidiacuda11.6.0-base-ubuntu20.04-python3.*BREAKING CHANGE: register functions to substratools is done with a decorator.
class MyAlgo:
def my_function1:
pass
def my_function2:
pass
if __name__ == '__main__':
tools.algo.execute(MyAlgo())
become
@tools.register
def my_function1:
pass
@tools.register
def my_function2:
pass
if __name__ == '__main__':
tools.execute()
Substra Backend:
Prevent use of
__in asset metadata keys
Substra 0.22.0 — 2022-10-20¶
Main changes
BREAKING CHANGE: the backend type is now set in the
Client, the env variableDEBUG_SPAWNERis not used anymore. Default value is deployed.
before:
export DEBUG_SPAWNER=subprocess
client = substra.Client(debug=True)
after:
client = substra.Client(backend_type=substra.BackendType.LOCAL_SUBPROCESS)
BREAKING CHANGE:
schemas.ComputePlanSpec.clean_modelsproperty is now removed, thetransientproperty on tasks outputs should be used instead.BREAKING CHANGE:
Model.categoryfield has been removed.BREAKING CHANGE:
trainandpredictmethods of all SubstraFL algos now takes datasamples as argument instead of X and y. This is impacting the user code only if he or she overwrite those methods instead of using the_local_trainand_local_predictmethods.BREAKING CHANGE: The result of the
get_datamethod from the opener is automatically provided to the given dataset as__init__arg instead of x and y within thetrainandpredictmethods of allTorchAlgoclasses. The user dataset should be adapted accordingly:
from torch.utils.data import Dataset
class MyDataset(Dataset):
def __init__(self, x, y, is_inference=False) -> None:
...
class MyAlgo(TorchFedAvgAlgo):
def __init__(
self,
):
torch.manual_seed(seed)
super().__init__(
model=my_model,
criterion=criterion,
optimizer=optimizer,
index_generator=index_generator,
dataset=MyDataset,
)
should be replaced with
from torch.utils.data import Dataset
class MyDataset(Dataset):
def __init__(self, datasamples, is_inference=False) -> None:
...
class MyAlgo(TorchFedAvgAlgo):
def __init__(
self,
):
torch.manual_seed(seed)
super().__init__(
model=my_model,
criterion=criterion,
optimizer=optimizer,
index_generator=index_generator,
dataset=MyDataset,
)
BREAKING CHANGE:
Algo.category: do not rely on categories anymore, all algo categories will be returned asUNKNOWN.BREAKING CHANGE: Replaced
algobyalgo_keyin ComputeTask.
GUI
Improved user management: the last admin cannot be deleted anymore.
Substra
Algo categories are not checked anymore in local mode. Validations based on inputs and outputs are sufficient.
Pass substra-tools arguments via a file instead of the command line. This fixes an issue where compute plan would not run if there was too many data samples.
SubstraFL
NOTABLE CHANGES due to breaking changes in substra-tools:
The opener only exposes
get_dataandfake_datamethods.The results of the above method is passed under the datasamples keys within the inputs dict arg of all tools methods (
train,predict,aggregate,score).All method (
train,predict,aggregate,score) now takes a task_properties argument (dict) in addition to inputs and outputs.The rank of a task previously passed under the rank key within the inputs is now given in the
task_propertiesdict under the rank key.
This means that all opener.py file should be changed from:
import substratools as tools
class TestOpener(tools.Opener):
def get_X(self, folders):
...
def get_y(self, folders):
...
def fake_X(self, n_samples=None):
...
def fake_y(self, n_samples=None):
...
to:
import substratools as tools
class TestOpener(tools.Opener):
def get_data(self, folders):
...
def fake_data(self, n_samples=None):
...
This also implies that metrics has now access to the results of get_data and not only get_y as previously. The user should adapt all of his metrics file accordingly e.g.:
class AUC(tools.Metrics):
def score(self, inputs, outputs):
"""AUC"""
y_true = inputs["y"]
...
def get_predictions(self, path):
return np.load(path)
if __name__ == "__main__":
tools.metrics.execute(AUC())
could be replace with:
class AUC(tools.Metrics):
def score(self, inputs, outputs, task_properties):
"""AUC"""
datasamples = inputs["datasamples"]
y_true = ... # getting target from the whole datasamples
def get_predictions(self, path):
return np.load(path)
if __name__ == "__main__":
tools.metrics.execute(AUC())
Substra 0.21.0 — 2022-09-12¶
This is our first open source release since 2021! When the product was closed source it used to be named Connect. It is now renamed Substra.
Main changes
Admin and user roles have been introduced. The user role is the same as the previous role. The admin role can, in addition, manage users and define their roles. The admin can create users and reset their password in the GUI.
BREAKING CHANGE: remove the shared local folder of the compute plan
BREAKING CHANGE: pass the algo method to execute under the
--method-nameargument within the within the cli of the task execution. If the interface between substra and the backend is handled via substratools, there are no changes to apply within the substra code but algo and metricDockerfilesshould expose a--method-nameargument in theENTRYPOINT.BREAKING CHANGE: an extra argument
predictions_pathhas been added to bothpredictand_local_predictmethods from allTorchAlgoclasses. The user now have to use the_save_predictionsmethod to save its predictions in_local_predict. The user defined metrics will load those saved prediction withnp.load(inputs['predictions']). The_save_predictionsmethod can be overwritten.
Default _local_predict method from SubstraFL algorithms went from:
def _local_predict(self, predict_dataset: torch.utils.data.Dataset):
if self._index_generator is not None:
predict_loader = torch.utils.data.DataLoader(predict_dataset, batch_size=self._index_generator.batch_size)
else:
raise BatchSizeNotFoundError(
"No default batch size has been found to perform local prediction. "
"Please overwrite the _local_predict function of your algorithm."
)
self._model.eval()
predictions = torch.Tensor([])
with torch.inference_mode():
for x in predict_loader:
predictions = torch.cat((predictions, self._model(x)), 0)
return predictions
to
def _local_predict(self, predict_dataset: torch.utils.data.Dataset, predictions_path: Path):
if self._index_generator is not None:
predict_loader = torch.utils.data.DataLoader(predict_dataset, batch_size=self._index_generator.batch_size)
else:
raise BatchSizeNotFoundError(
"No default batch size has been found to perform local prediction. "
"Please overwrite the _local_predict function of your algorithm."
)
self._model.eval()
predictions = torch.Tensor([])
with torch.inference_mode():
for x in predict_loader:
predictions = torch.cat((predictions, self._model(x)), 0)
self._save_predictions(predictions, predictions_path)
return predictions
GUI
GUI: the page size has been increased from 10 to 30 items displayed
GUI: Fixed: keep filtering/ordering setup when refreshing an asset list page
GUI: Fixed: filtering on compute plan duration
GUI: Fixed: the columns
name,statusanddatesare displayed by default in the compute plans pageGUI: Fixed: broken unselection of compute plans in comparison page
GUI: Fixed: CP columns and favorites disappear on logout
GUI: the CP workflow graph now displays CPs with up to 1000 tasks, instead of 300
The test task rank now have the same behaviour as for other tasks (parent task rank + 1)
Substra
added
list_modelto the SDK clientDownload function of the client return the path of downloaded file
Local mode: add a check, a task output of type performance must have public permissions
Fix the filters on status for compute plans and tasks. This fix also introduces some changes: the value for the filters on status must now be a list (like for other filters, there is a OR condition between elements of the list) and its value must be
substra.models.ComputePlanStatus.{name of the status}.valuefor compute plans andsubstra.models.Status.{name of the status}.valuefor tasks.Example:
# Return all the composite traintuples with the status "doing"
client.list_composite_traintuple(filters={"status": [substra.models.Status.doing.value]})
changed the
metricsandalgodefinition relying on substra tools. All the methods of those objects now takeinputsandoutputsas arguments; which areTypedDict.
SubstraFL
Throw an error if
pytorch 1.12.0is used. There is a regression bug intorch 1.12.0, that impacts optimizers that have been pickled and unpickled. This bug occurs for Adam optimizer for example (but not for SGD). Here is a link to one issue covering it: pytorch/pytorch#80345In the PyTorch algorithms, move the data to the device (GPU or CPU) in the training loop and predict function so that the user does not need to do it.