Overview¶
SubstraFL is a federated learning Python library that leverages Substra software to run federated learning experiments at scale on real distributed data. Its main usage is therefore in production environments. SubstraFL can also be used on a single machine on a virtually splitted dataset for two use cases:
to debug code before launching experiments on a real network
to perform FL simulations
SubstraFL uses the Substra library to handle creation and orchestration of tasks. Please note that SubstraFL is planned to be merged with Substra into a single library.
SubstraFL strives to be as flexible and modular as possible. You can easily change one part of the federated learning experiment (for instance, the local training algorithm) without having to change everything else (the federated learning strategy, the metrics, the dataset, etc)
ML framework compatibility: SubstraFL can be used with any machine learning framework (PyTorch, Tensorflow, Scikit-Learn, etc). However, a specific interface has been developed for using PyTorch with SubstraFL, which makes writing PyTorch code simpler than using other frameworks.
Installation¶
Substrafl and Substra are compatible with Python versions 3.8, 3.9 and 3.10 on Windows, MacOS and Linux.
Note
On Windows, please refer to Run tasks locally with the local mode to use the Docker mode.
To install SubstraFL run the following command:
$ pip install substrafl
Substra is a dependency of SubstraFL, so it will be automatically installed.
Main concepts¶
Experiment¶
An experiment is made up of all the different bricks needed to perform federated learning training and testing: the training data, the algorithm used to do the local training, the federated learning strategy, the metric and the test data. Launching an experiment creates a Compute plan.
Algorithm¶
Warning
A SubstraFL algorithm is not the same as a Substra Algorithm!
A SubstraFL algorithm contains the local training and predict code and all the associated hyper parameters (batch size, loss, optimizer, etc).
Evaluation Strategy¶
The evaluation strategy specifies how and when the model is tested. More specifically it defines:
on which test data the model is tested
at which rounds the model is tested
Metric¶
A metric is a function that computes a performance by comparing labels (ground truth) and model’s predictions. One or several metrics can be added for an Evaluation Strategy.
Index Generator¶
The notion of epochs does not fully apply to the FL setting. Usually we don’t want to train on a full epoch on each organization at every round, but on a reduced quantity of data to prevent models from different organizations from diverging too much.
In a federated setting, at each round, in each organization, the model is trained for num_updates batches, with each batch containing batch_size data points.
For instance if you have a dataset of 1000 data points at every organization, if you specify num_updates=10 and batch_size=32, at each round your model trains on 10x32=320 data points per organization.
The index generator remembers which data has been used in the previous rounds and generates the new batches so that the model is trained on the full dataset (given enough number of rounds and updates). When the whole dataset has been used, the index generator shuffles the data and starts generating batches from the whole dataset again.
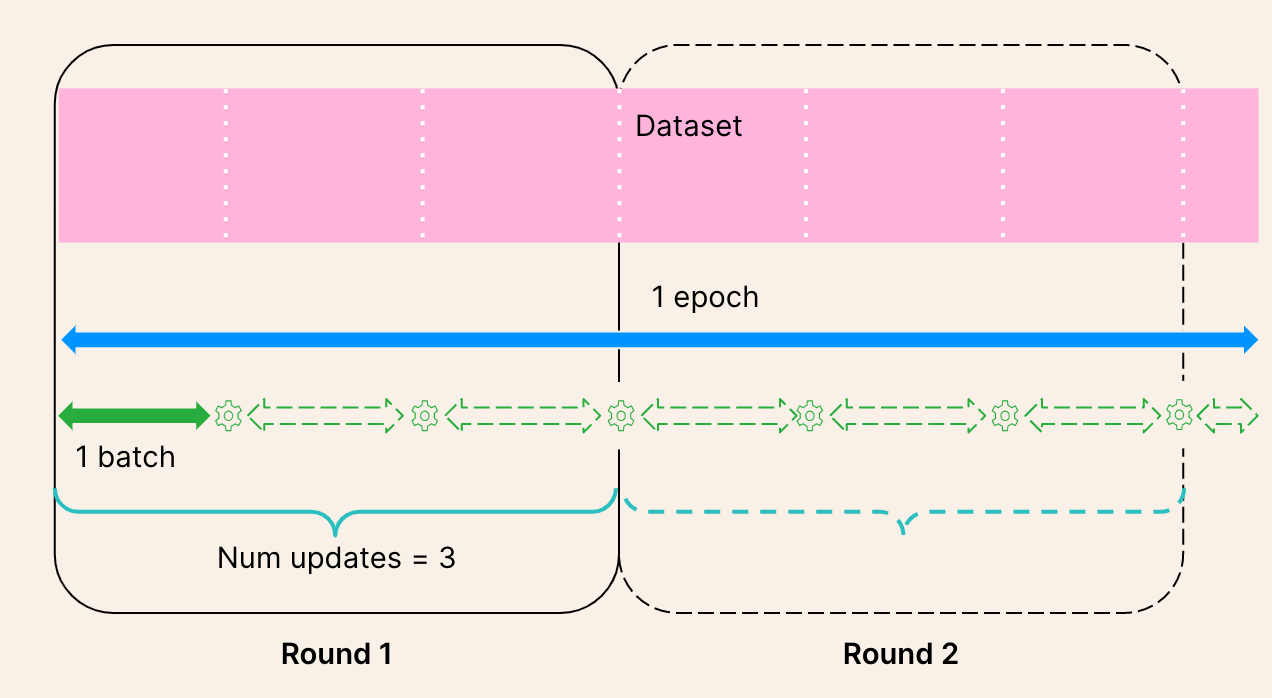
Example with three updates and two rounds¶
Node¶
There are three types of node:
TrainDataNode: one of the organizations the local training takes place on, with a set of data samples and an opener (a script used to load the data from files into memory) used for training.
TestDataNode: one of the organizations the model evaluation takes place on, with a set of data samples and an opener used for testing.
AggregationNode: the organization on which the aggregation, if there is one, takes place.
Note that organizations can be of any node type, and can be multiple node types at the same time. For instance one organization can be for one experiment a TrainDataNode and an AggregationNode.
Federated Learning Strategies¶
A FL strategy describes how to train a model on distributed data. The most well known strategy is the Federated Averaging strategy: train locally a model on every organization, then aggregate the weight updates from every organization, and then apply locally at each organization the averaged weight updates. A strategy imposes some constraints on the model that can be used. For instance, you can use the Federated Averaging strategy with a deep neural network or with a logistic regression but not with a random forest. Several FL Strategies are already implemented in SubstraFL.
Strategies can be centralized or decentralized:
A centralized FL strategy: during the training, the organization containing train data communicates exclusively with a central organization.
A decentralized FL strategy: during the training, the organizations communicate between themselves, there is no central organization.
Round¶
Each round represents one iteration of the training loop in the federated setting. For example, in a centralized federated learning strategy, a round consists of:
Initializing the same model (architecture and initial weights) on each training organization.
Each training organization locally trains the model on its own data and calculates the weight updates to send to the aggregator (and sometimes other statistics depending on the strategy).
The training organizations send the weight updates to the aggregator organization.
The weight updates are aggregated by the aggregator organization.
The aggregated organization sends the aggregated updates to the training organizations.
The training organizations update their model with the aggregated updates.
Now that you have a good overview of SubstraFL, have a look at the MNIST example.
Centralized strategy - workflow¶
Warning
This section is for advanced users who wants to know more on what happens under the Substra hood.
The workflow of a centralised strategy, unless specified otherwise, is as follows:
initialisation round: one train task on each train organization
then for each round: one aggregate task on the central organization then one train task on each train organization
Steps of an aggregate task:
Calculate the common shared state from the previous train tasks shared state.
Steps of a train task:
If there is an aggregate task before: update the model parameters with the shared state
Train the model on the local data
Calculate the shared state update
Reset the model parameters to before the local training
Output the local state (the model) and the shared state (parameters to aggregate)
So the local state that the train task outputs represents the state of the model just after the aggregation step of a federated learning strategy. This means that to test the output model of round 1, we can add a test task after the train task of round 1.
This also means that for the final round of the strategy, we do a useless step of training the model on the local data. This is for 2 reasons:
Be able to implement checkpointing more easily (ie resume the experiment where we left it, feature not yet available)
Reuse the same algo as the other train tasks, which speeds up the execution
For a more detailed example, see the Federated Averaging implementation.