Note
Click here to download the full example code
Substrafl FedAvg on MNIST dataset¶
This example illustrate the basic usage of Substrafl, and propose a model training by Federated Learning using de Federated Average strategy.
It is based on the MNIST Dataset of handwritten digits.
In this example, we work on the grayscale images of size 28x28 pixels. The problem considered is a classification problem aiming to recognize the number written on each image.
The objective of this example is to launch a federated learning experiment on two organizations, using the FedAvg strategy on a convolutional neural network (CNN) torch model.
This example does not use the deployed platform of Substra and will run in local mode.
Requirements:
To run this example locally, please make sure to download and unzip in the same directory as this example the assets needed to run it:
assets required to run this examplePlease ensure to have all the libraries installed, a requirements.txt file is included in the zip file, where you can run the command: pip install -r requirements.txt to install them.
Substra and Substrafl should already be installed, if not follow the instructions described here: Installation
Client and data preparation¶
Imports¶
import codecs
import os
import pathlib
import sys
import zipfile
import numpy as np
from torchvision.datasets import MNIST
Creating the Substra Client¶
We work with two different organizations, defined by their IDs. Both organizations provide a dataset. One of them will also provide the algorithm and # will register the machine learning tasks.
Once these variables defined, we can create our Substra Client.
This example runs in local mode, simulating a federated learning experiment.
from substra import Client
# Choose the subprocess mode to locally simulate the FL process
DEBUG_SPAWNER = "subprocess"
os.environ["DEBUG_SPAWNER"] = DEBUG_SPAWNER
# Create the substra clients
N_CLIENTS = 2
clients = [Client(debug=True) for _ in range(N_CLIENTS)]
clients = {client.organization_info().organization_id: client for client in clients}
# Store their IDs
ORGS_ID = list(clients.keys())
# The org id on which your computation tasks are registered
ALGO_ORG_ID = ORGS_ID[1]
# Create the temporary directory for generated data
(pathlib.Path.cwd() / "tmp").mkdir(exist_ok=True)
data_path = pathlib.Path.cwd() / "tmp" / "data"
assets_directory = pathlib.Path.cwd() / "assets"
Download and extract MNIST dataset¶
This section downloads (if needed) the MNIST dataset using the torchvision library. It extracts the images from the raw files and locally create two folders: one for each organization.
Each organization will have access to half the train data, and to half the test data (which correspond to 30,000 images for training and 5,000 for testing each).
def get_int(b: bytes) -> int:
return int(codecs.encode(b, "hex"), 16)
def MNISTraw2numpy(path: str, strict: bool = True) -> np.array:
# read
with open(path, "rb") as f:
data = f.read()
# parse
magic = get_int(data[0:4])
nd = magic % 256
assert 1 <= nd <= 3
numpy_type = np.uint8
s = [get_int(data[4 * (i + 1) : 4 * (i + 2)]) for i in range(nd)]
num_bytes_per_value = np.iinfo(numpy_type).bits // 8
# The MNIST format uses the big endian byte order. If the system uses little endian byte order by default,
# we need to reverse the bytes before we can read them with np.frombuffer().
needs_byte_reversal = sys.byteorder == "little" and num_bytes_per_value > 1
parsed = np.frombuffer(bytearray(data), dtype=numpy_type, offset=(4 * (nd + 1)))
if needs_byte_reversal:
parsed = parsed.flip(0)
assert parsed.shape[0] == np.prod(s) or not strict
return parsed.reshape(*s)
raw_path = pathlib.Path(data_path) / "MNIST" / "raw"
# Download the dataset
MNIST(data_path, download=True)
# Extract numpy array from raw data
train_images = MNISTraw2numpy(str(raw_path / "train-images-idx3-ubyte"))
train_labels = MNISTraw2numpy(str(raw_path / "train-labels-idx1-ubyte"))
test_images = MNISTraw2numpy(str(raw_path / "t10k-images-idx3-ubyte"))
test_labels = MNISTraw2numpy(str(raw_path / "t10k-labels-idx1-ubyte"))
# Split array into the number of organization
train_images_folds = np.split(train_images, N_CLIENTS)
train_labels_folds = np.split(train_labels, N_CLIENTS)
test_images_folds = np.split(test_images, N_CLIENTS)
test_labels_folds = np.split(test_labels, N_CLIENTS)
# Save splits in different folders to simulate the different organization
for i in range(N_CLIENTS):
# Save train dataset on each org
os.makedirs(str(data_path / f"org_{i+1}/train"), exist_ok=True)
filename = data_path / f"org_{i+1}/train/train_images.npy"
np.save(str(filename), train_images_folds[i])
filename = data_path / f"org_{i+1}/train/train_labels.npy"
np.save(str(filename), train_labels_folds[i])
# Save test dataset on each org
os.makedirs(str(data_path / f"org_{i+1}/test"), exist_ok=True)
filename = data_path / f"org_{i+1}/test/test_images.npy"
np.save(str(filename), test_images_folds[i])
filename = data_path / f"org_{i+1}/test/test_labels.npy"
np.save(str(filename), test_labels_folds[i])
Out:
Downloading http://yann.lecun.com/exdb/mnist/train-images-idx3-ubyte.gz
Downloading http://yann.lecun.com/exdb/mnist/train-images-idx3-ubyte.gz to /home/docs/checkouts/readthedocs.org/user_builds/owkin-substra-documentation/checkouts/0.21.0/substrafl_examples/strategies_examples/tmp/data/MNIST/raw/train-images-idx3-ubyte.gz
0%| | 0/9912422 [00:00<?, ?it/s]
9913344it [00:00, 99128335.05it/s]
9913344it [00:00, 98787074.38it/s]
Extracting /home/docs/checkouts/readthedocs.org/user_builds/owkin-substra-documentation/checkouts/0.21.0/substrafl_examples/strategies_examples/tmp/data/MNIST/raw/train-images-idx3-ubyte.gz to /home/docs/checkouts/readthedocs.org/user_builds/owkin-substra-documentation/checkouts/0.21.0/substrafl_examples/strategies_examples/tmp/data/MNIST/raw
Downloading http://yann.lecun.com/exdb/mnist/train-labels-idx1-ubyte.gz
Downloading http://yann.lecun.com/exdb/mnist/train-labels-idx1-ubyte.gz to /home/docs/checkouts/readthedocs.org/user_builds/owkin-substra-documentation/checkouts/0.21.0/substrafl_examples/strategies_examples/tmp/data/MNIST/raw/train-labels-idx1-ubyte.gz
0%| | 0/28881 [00:00<?, ?it/s]
29696it [00:00, 71377679.99it/s]
Extracting /home/docs/checkouts/readthedocs.org/user_builds/owkin-substra-documentation/checkouts/0.21.0/substrafl_examples/strategies_examples/tmp/data/MNIST/raw/train-labels-idx1-ubyte.gz to /home/docs/checkouts/readthedocs.org/user_builds/owkin-substra-documentation/checkouts/0.21.0/substrafl_examples/strategies_examples/tmp/data/MNIST/raw
Downloading http://yann.lecun.com/exdb/mnist/t10k-images-idx3-ubyte.gz
Downloading http://yann.lecun.com/exdb/mnist/t10k-images-idx3-ubyte.gz to /home/docs/checkouts/readthedocs.org/user_builds/owkin-substra-documentation/checkouts/0.21.0/substrafl_examples/strategies_examples/tmp/data/MNIST/raw/t10k-images-idx3-ubyte.gz
0%| | 0/1648877 [00:00<?, ?it/s]
1649664it [00:00, 38670908.56it/s]
Extracting /home/docs/checkouts/readthedocs.org/user_builds/owkin-substra-documentation/checkouts/0.21.0/substrafl_examples/strategies_examples/tmp/data/MNIST/raw/t10k-images-idx3-ubyte.gz to /home/docs/checkouts/readthedocs.org/user_builds/owkin-substra-documentation/checkouts/0.21.0/substrafl_examples/strategies_examples/tmp/data/MNIST/raw
Downloading http://yann.lecun.com/exdb/mnist/t10k-labels-idx1-ubyte.gz
Downloading http://yann.lecun.com/exdb/mnist/t10k-labels-idx1-ubyte.gz to /home/docs/checkouts/readthedocs.org/user_builds/owkin-substra-documentation/checkouts/0.21.0/substrafl_examples/strategies_examples/tmp/data/MNIST/raw/t10k-labels-idx1-ubyte.gz
0%| | 0/4542 [00:00<?, ?it/s]
5120it [00:00, 36835054.00it/s]
Extracting /home/docs/checkouts/readthedocs.org/user_builds/owkin-substra-documentation/checkouts/0.21.0/substrafl_examples/strategies_examples/tmp/data/MNIST/raw/t10k-labels-idx1-ubyte.gz to /home/docs/checkouts/readthedocs.org/user_builds/owkin-substra-documentation/checkouts/0.21.0/substrafl_examples/strategies_examples/tmp/data/MNIST/raw
Registering assets¶
Substra and Substrafl imports¶
from substra.sdk.schemas import (
DatasetSpec,
AlgoInputSpec,
AlgoOutputSpec,
AssetKind,
Permissions,
DataSampleSpec,
AlgoCategory,
AlgoSpec,
)
from substrafl.nodes import TestDataNode, TrainDataNode
Permissions¶
As data can not be seen once it is registered on the platform, we set Permissions for each Assets define their access rights to the different data.
The metadata are visible by all the users of a Channel.
permissions = Permissions(public=False, authorized_ids=ORGS_ID)
Registering dataset¶
A Dataset is composed of an opener, which is a Python script with the instruction of how to load the data from the files in memory, and a description markdown file.
dataset = DatasetSpec(
name="MNIST",
type="npy",
data_opener=assets_directory / "dataset" / "opener.py",
description=assets_directory / "dataset" / "description.md",
permissions=permissions,
logs_permission=permissions,
)
Adding Metrics¶
A metric corresponds to an algorithm used to compute the score of predictions on a datasample. Concretely, a metric corresponds to an archive (tar or zip file), automatically build from:
a Python scripts that implement the metric computation
a Dockerfile to specify the required dependencies of the Python scripts
inputs_metrics = [
AlgoInputSpec(identifier="datasamples", kind=AssetKind.data_sample, optional=False, multiple=True),
AlgoInputSpec(identifier="opener", kind=AssetKind.data_manager, optional=False, multiple=False),
AlgoInputSpec(identifier="predictions", kind=AssetKind.model, optional=False, multiple=False),
]
outputs_metrics = [AlgoOutputSpec(identifier="performance", kind=AssetKind.performance, multiple=False)]
objective = AlgoSpec(
category=AlgoCategory.metric,
inputs=inputs_metrics,
outputs=outputs_metrics,
name="Accuracy",
description=assets_directory / "metric" / "description.md",
file=assets_directory / "metric" / "metrics.zip",
permissions=permissions,
)
METRICS_DOCKERFILE_FILES = [
assets_directory / "metric" / "metrics.py",
assets_directory / "metric" / "Dockerfile",
]
archive_path = objective.file
with zipfile.ZipFile(archive_path, "w") as z:
for filepath in METRICS_DOCKERFILE_FILES:
z.write(filepath, arcname=filepath.name)
metric_key = clients[ALGO_ORG_ID].add_algo(objective)
Train and test data nodes¶
The Dataset object itself does not contain the data. The proper asset to access them is the datasample asset.
A datasample contains a local path to the data, and the key identifying the Dataset it is based on, in order to have access to the proper opener.py file.
Now that all our Assets are well defined, we can create TrainDataNode and TestDataNode to gathered the Dataset and the datasamples on the specified nodes.
train_data_nodes = list()
test_data_nodes = list()
for ind, org_id in enumerate(ORGS_ID):
client = clients[org_id]
# Add the dataset to the client to provide access to the opener in each organization.
dataset_key = client.add_dataset(dataset)
assert dataset_key, "Missing data manager key"
# Add the training data on each organization.
data_sample = DataSampleSpec(
data_manager_keys=[dataset_key],
test_only=False,
path=data_path / f"org_{ind+1}" / "train",
)
train_datasample_key = client.add_data_sample(
data_sample,
local=True,
)
# Create the Train Data Node (or training task) and save it in a list
train_data_node = TrainDataNode(
organization_id=org_id,
data_manager_key=dataset_key,
data_sample_keys=[train_datasample_key],
)
train_data_nodes.append(train_data_node)
# Add the testing data on each organization.
data_sample = DataSampleSpec(
data_manager_keys=[dataset_key],
test_only=True,
path=data_path / f"org_{ind+1}" / "test",
)
test_datasample_key = client.add_data_sample(
data_sample,
local=True,
)
# Create the Test Data Node (or testing task) and save it in a list
test_data_node = TestDataNode(
organization_id=org_id,
data_manager_key=dataset_key,
test_data_sample_keys=[test_datasample_key],
metric_keys=[metric_key],
)
test_data_nodes.append(test_data_node)
Machine Learning specification¶
Torch imports¶
import torch
from torch import nn
import torch.nn.functional as F
CNN definition¶
We choose to use a classic torch CNN as the model to train. The model structure is defined by the user independently of Substrafl.
seed = 42
torch.manual_seed(seed)
class CNN(nn.Module):
def __init__(self):
super(CNN, self).__init__()
self.conv1 = nn.Conv2d(1, 32, kernel_size=5)
self.conv2 = nn.Conv2d(32, 32, kernel_size=5)
self.conv3 = nn.Conv2d(32, 64, kernel_size=5)
self.fc1 = nn.Linear(3 * 3 * 64, 256)
self.fc2 = nn.Linear(256, 10)
def forward(self, x, eval=False):
x = F.relu(self.conv1(x))
x = F.relu(F.max_pool2d(self.conv2(x), 2))
x = F.dropout(x, p=0.5, training=not eval)
x = F.relu(F.max_pool2d(self.conv3(x), 2))
x = F.dropout(x, p=0.5, training=not eval)
x = x.view(-1, 3 * 3 * 64)
x = F.relu(self.fc1(x))
x = F.dropout(x, p=0.5, training=not eval)
x = self.fc2(x)
return F.log_softmax(x, dim=1)
model = CNN()
optimizer = torch.optim.Adam(model.parameters(), lr=0.001)
criterion = torch.nn.CrossEntropyLoss()
Substrafl imports¶
from typing import Any
from substrafl.algorithms.pytorch import TorchFedAvgAlgo
from substrafl.dependency import Dependency
from substrafl.strategies import FedAvg
from substrafl.nodes import AggregationNode
from substrafl.evaluation_strategy import EvaluationStrategy
from substrafl.index_generator import NpIndexGenerator
from substrafl.experiment import execute_experiment
Substrafl algo definition¶
To instantiate a Substrafl Torch Algorithms, you need to define a torch Dataset with a specific __init__ signature, that must contain (self, x, y, is_inference). This torch Dataset is useful to preprocess your data on the __getitem__ function. The __getitem__ function is expected to return x and y if is_inference is False, else x. This behavior can be changed by re-writing the _local_train or predict methods.
This dataset is passed as a class to the Torch Algorithms. Indeed, this torch Dataset will be instantiated within the algorithm, using the opener functions as x and y parameters.
The index generator will be used a the batch sampler of the dataset, in order to save the state of the seen samples during the training, as Federated Algorithms have a notion of num_updates, which forced the batch sampler of the dataset to be stateful.
# Number of model update between each FL strategy aggregation.
NUM_UPDATES = 15
# Number of samples per update.
BATCH_SIZE = 32
index_generator = NpIndexGenerator(
batch_size=BATCH_SIZE,
num_updates=NUM_UPDATES,
)
class TorchDataset(torch.utils.data.Dataset):
def __init__(self, x, y, is_inference: bool):
self.x = x
self.y = y
self.is_inference = is_inference
def __getitem__(self, idx):
if not self.is_inference:
return self.x[idx] / 255, self.y[idx]
else:
return self.x[idx] / 255
def __len__(self):
return len(self.x)
class MyAlgo(TorchFedAvgAlgo):
def __init__(self):
super().__init__(
model=model,
criterion=criterion,
optimizer=optimizer,
index_generator=index_generator,
dataset=TorchDataset,
seed=seed,
)
Algo dependencies¶
The dependencies needed for the Torch Algorithms are specified by a Dependency object, in order to install the right library in the Python environment of each organization.
algo_deps = Dependency(pypi_dependencies=["numpy==1.23.1", "torch==1.11.0"])
Federated Learning strategies¶
For this example, we choose to use the Federated averaging Strategy (Strategies), based on the FedAvg paper by McMahan et al., 2017.
strategy = FedAvg()
Running the experiment¶
We now have all the necessary objects to launch our experiment. Below a summary of all the objects we created so far:
A Client to orchestrate all the assets of our project, using their keys to identify them
An Torch Algorithms, to define the training parameters (optimizer, train function, predict function, etc…)
A Strategies, to specify the federated learning aggregation operation
TrainDataNode, to indicate where we can process training task, on which data and using which opener
An Evaluation Strategy, to define where and at which frequency we evaluate the model
An AggregationNode, to specify the node on which the aggregation operation will be computed
The number of round, a round being defined by a local training step followed by an aggregation operation
An experiment folder to save a summary of the operation made
The Dependency to define the libraries the experiment needs to run.
aggregation_node = AggregationNode(ALGO_ORG_ID)
my_eval_strategy = EvaluationStrategy(test_data_nodes=test_data_nodes, rounds=1)
# Number of time to apply the compute plan.
NUM_ROUNDS = 3
compute_plan = execute_experiment(
client=clients[ALGO_ORG_ID],
algo=MyAlgo(),
strategy=strategy,
train_data_nodes=train_data_nodes,
evaluation_strategy=my_eval_strategy,
aggregation_node=aggregation_node,
num_rounds=NUM_ROUNDS,
experiment_folder=str(pathlib.Path.cwd() / "tmp" / "experiment_summaries"),
dependencies=algo_deps,
)
Out:
/home/docs/checkouts/readthedocs.org/user_builds/owkin-substra-documentation/checkouts/0.21.0/docs/src/substra/substra/sdk/backends/local/backend.py:400: UserWarning: 'clean_models=True' is ignored on the local backend.
warnings.warn("'clean_models=True' is ignored on the local backend.")
Compute plan progress: 0%| | 0/23 [00:00<?, ?it/s]
Compute plan progress: 4%|4 | 1/23 [00:01<00:35, 1.62s/it]
Compute plan progress: 9%|8 | 2/23 [00:03<00:34, 1.65s/it]
Compute plan progress: 13%|#3 | 3/23 [00:03<00:22, 1.10s/it]
Compute plan progress: 17%|#7 | 4/23 [00:05<00:24, 1.31s/it]
Compute plan progress: 22%|##1 | 5/23 [00:07<00:25, 1.43s/it]
Compute plan progress: 26%|##6 | 6/23 [00:07<00:18, 1.10s/it]
Compute plan progress: 30%|### | 7/23 [00:10<00:27, 1.73s/it]
Compute plan progress: 35%|###4 | 8/23 [00:13<00:32, 2.15s/it]
Compute plan progress: 39%|###9 | 9/23 [00:15<00:27, 1.99s/it]
Compute plan progress: 43%|####3 | 10/23 [00:16<00:24, 1.88s/it]
Compute plan progress: 48%|####7 | 11/23 [00:17<00:19, 1.64s/it]
Compute plan progress: 52%|#####2 | 12/23 [00:18<00:16, 1.46s/it]
Compute plan progress: 57%|#####6 | 13/23 [00:19<00:11, 1.16s/it]
Compute plan progress: 61%|###### | 14/23 [00:22<00:15, 1.76s/it]
Compute plan progress: 65%|######5 | 15/23 [00:25<00:17, 2.14s/it]
Compute plan progress: 70%|######9 | 16/23 [00:27<00:13, 1.98s/it]
Compute plan progress: 74%|#######3 | 17/23 [00:28<00:11, 1.88s/it]
Compute plan progress: 78%|#######8 | 18/23 [00:29<00:08, 1.64s/it]
Compute plan progress: 83%|########2 | 19/23 [00:30<00:05, 1.46s/it]
Compute plan progress: 87%|########6 | 20/23 [00:34<00:05, 1.94s/it]
Compute plan progress: 91%|#########1| 21/23 [00:36<00:04, 2.25s/it]
Compute plan progress: 96%|#########5| 22/23 [00:38<00:01, 1.89s/it]
Compute plan progress: 100%|##########| 23/23 [00:39<00:00, 1.64s/it]
Compute plan progress: 100%|##########| 23/23 [00:39<00:00, 1.70s/it]
Listing results¶
import pandas as pd
performances_df = pd.DataFrame(client.get_performances(compute_plan.key).dict())
print("\nPerformance Table: \n")
print(performances_df[["worker", "round_idx", "performance"]])
Out:
Performance Table:
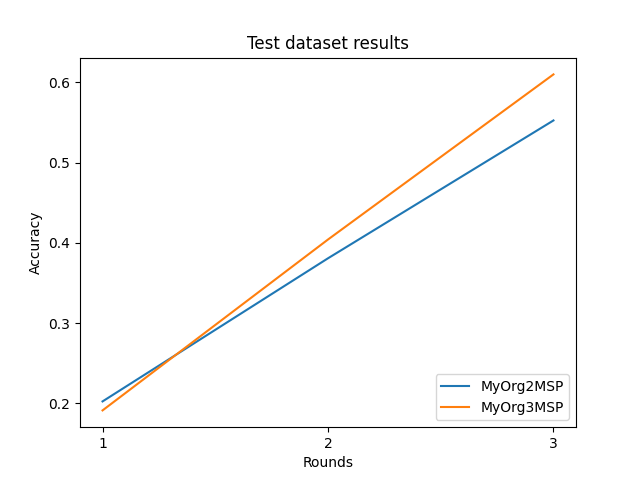
worker round_idx performance
0 MyOrg2MSP 1 0.2024
1 MyOrg3MSP 1 0.1912
2 MyOrg2MSP 2 0.3808
3 MyOrg3MSP 2 0.4042
4 MyOrg2MSP 3 0.5526
5 MyOrg3MSP 3 0.6100
Plot results¶
import matplotlib.pyplot as plt
plt.title("Test dataset results")
plt.xlabel("Rounds")
plt.ylabel("Accuracy")
for id in ORGS_ID:
df = performances_df.query(f"worker == '{id}'")
plt.plot(df["round_idx"], df["performance"], label=id)
plt.legend(loc="lower right")
plt.show()
Total running time of the script: ( 0 minutes 41.247 seconds)